검색결과 리스트
Sutdy...에 해당되는 글 74건
- 2008.11.27 [베가스] Chapter#3 영상에 효과넣기
- 2008.11.27 [베가스] Chapter#2 영상의 분리와 병합
- 2008.11.27 [베가스] Chapter#1 기본구성과 파일의 이동방법
- 2008.11.27 어셈블리언어 기초
- 2008.11.27 어셈블리어를 배우기 위한 기본개념 (3)
- 2008.11.27 어셈블리어를 배우기 위한 기본개념 (2)
- 2008.11.27 어셈블리어를 배우기 위한 기본개념 (1)
- 2008.11.27 어셈블리어 이해하기 < 강좌 소개 및 목차 >
- 2008.08.30 0의제곱은..?
- 2008.08.30 0! = 1인 세가지 이유... 3
글
이번 장에서는 2장에 이어서 영상소스 편집에 대해 계속 알아보겠습니다.
소스를 자르고 이동하고 추가하는 등에 대해서는 충분히 아셨으리라 생각합니다.
이제는 그 사이사이에 좀 더 멋진 영상연출을 위해
'효과' 넣어주는 방법을 살펴보죠.

실제 예를 통해 대표적인 효과 몇 가지 넣는 법을 보여드리겠습니다.
1. Transitions
이 효과는 영상과 영상 사이사이에 넣어주게 되어있습니다.
해당 효과연출을 위해서는 영상을 분리하거나 새로운 영상을 추가시켜야겠죠?
이 부분은 2장에서 배웠으니 넘어가겠습니다.
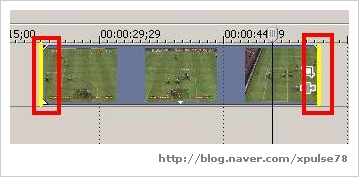
위 사진처럼 하나의 영상을 둘로 잘랐습니다.
그리고 아래 사진처럼 잘려진 오른쪽부분을 왼쪽으로 이동하여 겹치기했습니다.
영상이든 소리든 겹쳐지게 되면 물결표시가 나타나는데
이는 자연스러운 장면(소리)전환을 표현해주는 기능이며 디폴트상태가 자동설정입니다.
작업파일을 겹치면 자동적으로 연출됩니다.
이 겹쳐지는 부분이 넓을수록 효과가 천천히 나타나고
작을수록 빠르게 전환이 이루어지게 됩니다.













설정
트랙백
댓글
글
이번 장에서는 1장 마지막에서 말씀드린 것처럼 영상편집의
기본적인 스킬이라 할 수 있는 영상의 분리와 병합에 대해 알려드리겠습니다.
미리 말씀드리지만 영상이나 소리나 작업방식은 같습니다.
영상을 중심으로 설명해드리지만 소리쪽에도 똑같이 적용됨을 알아두시기 바랍니다.
음성파일의 편집에 대해서는 추후 따로 올려드리겠습니다.
자, 그럼 본격적으로 들어가겠습니다. 아래 사진에 주목해 주세요.

1장에서 영상소스와 사운드소스의 구성을 보여드렸으니 어느 부분이 영상부분인지는 아시겠죠?
아래 사운드부분은 잊고 이제부터 위에 영상부분에만 집중하시기 바랍니다.
A와 B로 나누어져있는 것이 보입니까?
실제로는 A와 B가 붙어있던 영상부분입니다.
이는 이렇게 뒤집어서 생각해볼 수 있습니다.
1. 원래 하나였던 A와B부분 사이에 효과를 넣어주기 위해 두 개로 나누었든가
2. 원래 존재하던 A부분에 새롭게 B라는 영상을 추가시켰든가
1번의 경우 영상을 쪼개조야겠죠? 원하는 영상부분에 마우스를 클릭합니다.

그러면 위에서처럼 그 부분이 선택이 되겠지요?
위 상태에서 'S'키를 가차없이 눌러줍니다.
그러면



분리되어진 한 부분을 새롭게 추가된 영상으로 생각한다면
2번의 경우는 자연스럽게 해결이 되겠군요.
1장에서 사운드파일을 추가한 것처럼 영상파일도 이렇게 덧붙일 수 있습니다.
추가적인 영상소스를 덧붙이든 기존의 소스를 나누던간에
그것으로 끝나면 재미없겠죠?
다음장에서는 영상파일에 다양한 효과넣는 방법에 대해 알아보도록 하겠습니다.
마치기 전에 초간단 팁하나 던지고 물러가겠습니다.
작업하시다 보면 미처 저장을 하지 못한 상태에서 실수할 때가 있는데 그럴 경우는

설정
트랙백
댓글
글
대부분 동영상편집프로그램으로 프리미어 또는 베가스를 많이 사용합니다.
그 중 조작이 간단하며 금방 배울 수 있는 베가스에 대해서 알려드리겠습니다.
쉽게 영상편집에 접근할 수 있는 큰 틀을 기준으로 설명하겠습니다.



설정
트랙백
댓글
글
이번 강좌에서는 어셈블리어로 프로그램을 작성하기 위해 필요한 기본 지식들을 배우게 될 것이다. 즉, 자료형과 간단한 명령어, 코딩할 때 알아야할 기반 지식들을 배우게 될 것이다. C언어를 처음 배울 때 #include
여기에 나올 간단한 예제들을 직접 해보고 싶다면, 최신버젼을 구해서 해보기 바란다. 그리고 이 강좌 소개및 목차부분에서 언급한 책에서 제공하는 라이브러리도 사용하게 될 것이다. 라이브러리라고 해서 특별한 것은 없다. 단지, 우리가 수행한 것이 제대로 되었나 출력해 봐야하는데, 많이 배우지 못한 상태에서 복잡한 출력 루틴을 만드는 것보다는 다른 라이브러리를 이용해 일단은 기본개념을 배우는 것이 좋기 때문이다. 그럼 이제 시작해 보자.
어셈블리의 기본적인 구성요소로는, 정수 상수, 정수 수식, 실수 상수, 문자 상수, 문자열 상수, 예약어, 식별자, 디렉티브(Directives), 인스트럭션(Instructions), 레이블(Label)등이 있다.
상수란 결국에 어떤 한 값인데, 코드에 숫자 그대로 입력되어 실행중에 값을 변경할 수 없거나, 변수이지만 값을 변경시킬수 없는 것을 의미한다. 먼저 정수 상수에 대해 알아보자.
정수 상수는 우리가 흔히 쓰는 표기대로 부호는 있거나 없어도 되고, 없다면 양수로 취급된다. 단지 다른 것이 있다면, 숫자 뒤에 radix라는 것을 붙여주는데 쉽게 이야기하면 진법을 이야기 하는 것이다. 우리가 이진수를 1010(2)라고 쓰고, 8진수를 777(8)이라고 수학에서 사용하듯이, 이곳에서도 뒤에 진법을 표기해 준다. 물론 뒤에 진법을 표기하지 않는다면 십진수로 취급된다.
다음 표1을 보면 쉽게 이해가 갈 것이다. 참고로 radix에는 실수를 표현하기 위한 것으로 r도 올 수 있는데, 이는 실수가 메모리에 저장되는 방식을 직접 우리가 기술하는 것이다. 그다지 본 강좌의 목적과 부합하지 않으므로 자세한 설명은 생략하겠다.
|
h |
16진수 |
|
q 또는 o |
8진수 |
|
d 또는 t |
10진수 |
|
b 또는 y |
이진수 |
이번에는 실수 상수에 대해 알아보자. 실수 역시 부호 규칙을 정수와 같다. 하지만 26과 26.은 다르다는 사실을 아는가? 실수는 반드시 .을 포함하고 있어야 한다. 26은 정수이고 26.은 실수이다. 정수와 실수는 컴퓨터에서 저장하는 형식이 다르다는 것은 알고 있으리라 믿는다. 또, 과학적 표기법을 사용할 수 있는데, 다음을 보아라.
-44.2E+5C에서도 이런 것을 본 적이 있을 것이다. E는 exponent를 뜻하고 그냥 과학적 표기법을 표시하기 위해서 사용한다고 생각하면된다. 저 위에 있는 것을 풀어 이야기하면 "-44.2 곱하기 10의 +5승"이다. 뒤에 +5대신 -2가 온다면 "-44.2 곱하기 10의 -2승"이 될 것이다.
다음은 문자 상수이다. 어셈블리어에 내가 한 글자를 표현하고 싶다면 작은따옴표(')나 큰 따옴표를 이용해 묶으면 된다. 이 둘의 차이는 없다. C처럼 큰 따옴표를 사용한다고 문자열인 것은 아니니, 헷갈리지 않길 바란다.
'A'라고 쓰면 사실 코드에는 그렇게 보이지만 어셈블할 때(즉, 컴파일할 때) 이는 A에 해당되는 아스키코드로 변환된다. 즉, 정수와 같다는 이야기가 된다. 달리 특별한 것으로 착각하지 않길 바란다.
이번엔 문자열 상수에 대해 알아보자. 문자열 상수 역시 문자상수처럼 작은 따옴표 또는 큰 따옴표로 표기된다. 혹시라도 문자열 안에 따옴표를 쓰고 싶다면 다음과 같이 하면 된다.
'I said "Hi, internet.com.".'
즉, 안쪽에 큰 따옴표를 쓰고싶다면 문자열의 시작과 끝을 나타내는 기호로 작은 따옴표를 사용하면 된다.
예약어란, 어셈블리언어가 먼저 사용하고 있는 단어들을 의미한다. C언어에서 예를 든다면 int같은 것이 있을 것이다.
- 인스트럭션 니모닉(Instruction mnemonics) : CPU에게 직접 내리는 명령(Instruction)이다.
- 디렉티브(Directives) : 어셈블리어에게 어떻게 어셈블할 것인지 지시해준다.
- 속성(Attributes) : BYTE와 WORD같이 변수등이 어떤 크기에 어떤정보를 담고 있을지를 알려주는 단어이다.
- 연산자(Operators) : 상수 수식에 사용되는 연산기호(*, +, -, / 같은 것들)를 뜻한다.
- 미리정의된 기호(Predefined Symbols) : @data와 같이 어셈블할 때 특정 값을 갖게되는 기호이다.
갑자기 이런 개념들이 나와 헷갈릴지 모르겠지만, 조금있다가 설명할 것이니 이런 것이 있구나, 하고 넘어가주길 바란다.
식별자는 프로그래머가 선택하는 이름이다. 변수이름, 상수이름, 프로시져(쉽게 말해서 함수)이름, 코드 레이블(label) 와 같은 것들이며, 다음의 규칙을 갖는다.
- 길이는 1~247글자이다.
- 대소문자를 구분하지 않는다. 즉, A와 a는 같다.
- 첫번째 글자는 반드시 (A~Z, a~z, _, @, $)중의 하나가 와야한다. 두번째 이상의 글자부터는 숫자가 올 수도 있다.
- 식별자는 예약어와 같아서는 안된다(위에 예약어에 대해 설명해 놓았다).
참고로, @로 시작하는 식별자는 되도록 쓰지 않는 것이 좋다. 어셈블러가 미리정의해 놓은 기호로 자주 사용되기 때문이다.
디렉티브(Directive)는 CPU에 직접 프로그래머가 명령을 내리는 것이 아닌, 어셈블러가 어셈블 할 때(컴파일 할 때) 해석하여 특정 일을 수행해 주는 명령을 이야기한다. 디렉티브는 주로 세그먼트, 메모리 모델 설정, 변수 정의, 프로시져(함수)만들 때 사용된다. 즉, 일종의 어셈블러 문법인 셈이다. 여기서도 대소문자는 구분하지 않는다.
.data와 .DATA는 같은 것으로 인식된다. 다음에 나올 인스트럭션(Instruction)과 비교해 보면 그 차이를 짐작할 수 있을 것이다.
인스트럭션은 네 부분으로 구성된다.
레이블: 니모닉 피연산자 ; 주석
Label: Mnemonic Operand(s) ; Comment
흔히 하나의 인스트럭션은 위와같이 구성되는데, Label과 Comment는 선택 사항이다. 단, Mnemonic은 반드시 있어야 하며, Mnemonic에 따라 Operand의 개수와 형(위에서말한 속성(attributes))이 결정된다. Instruction Mnemonic은 단지 CPU에 내리는 명령코드를 이해하기 쉽게 영문약자로 표시해준 것이고, Instruction은 피연산자와 부수적인 것들을 포함한 완전한 명령을 의미한다.
사소한 것이지만, 헷갈리지 않도록 한다. 레이블은 반드시 그 뒤에 콜론(:)이 붙어야 하며 주석은 반드시 그 앞에 (;)가 붙어야 한다. 이는 C++에서 // 와 같은 기능을 한다.
이제 이 네가지를 하나하나 살펴보기로 한다. 다음 페이지를 보라!
레이블이란 인스트럭션이나 데이터의 위치를 표시해 주는 것이다. 인스트럭션의 위치를 표시해 주는 것이라는 설명에 대해서는 C에서 goto문을 생각하면 가장 쉬울 것이다. C에서는 특정 문장 앞에 L1: 과같이 쓰고, 나중에 그 위치로 옮겨가고 싶을 때 goto L1;이라고 썼다. 어셈블리에서는 jmp이나 loop와 같은 인스트럭션을 쓸 때 사용하게 될 것이다. 이러할 때 쓰이는 레이블을 코드 레이블(Code Label)이라고 한다.
데이터의 위치를 표시해 준다는 것은 무엇일까? 바로 변수의 이름이다. 변수의 이름이란, 데이터 영역에 일종의 레이블을 붙여 그 위치를 기억했다가 그 변수를 사용할 때 아까 기억해놓은 레이블을 이용해서 그곳에 값을 저장하거나 불러오는데 쓰인다.
만약 데이터 레이블이 없다면 우리는 특정 주소에 변수를 사용하기로 약속하고는 그 주소를 계속 외우고 다녀야 할 것이다. 또 그 변수의 역할, 갖게될 값의 형태까지 기억하려면 얼마나 불편한지 짐작이 갈 것이다. 이렇게 데이터의 위치를 기억하는 레이블을 데이터 레이블(Data Label)이라고 한다.
아까 인스트럭션 니모닉에 대해 잠시 언급한 바가 있다. 좀더 자세히 설명해 보자면, Mnemonic의 사전적 의미는 "기억을 도와주는 장치" 이다. 1회에서 필자가 말했던 것 처럼 CPU에게 내릴 명령코드를 의미있는 글자로 치환시켜주는 것이 어셈블리어의 기본 모토라고 하였다. 복잡한 명령 코드 대신 "기억을 도와주는 것"이 바로 이 니모닉이다. 대표적인 것으로 mov, add, sub와 같은 것이 있다. mov는 move의 약자이고, sub는 subtract의 약자이니까 어떤 일을 하는 인스트럭션인지는 짐작이 갈 것이다.
주석은 코드 자체가 수행할 일들과는 무관하지만, 보는 이로 하여금 좀더 쉽게 이해할 수 있도록 도와주는 것이다. 즉, 이부분에서 어떤 일을 하는지, 주의할 점은 무엇인지 등이다. 특히 어셈블리어는 프로시져가 어떤일을 하는지, 매개변수는 어떤 것을 받는지, 리턴값은 어떤지에 대해 주석을 달지 않으면 해석하기가 정말 힘들다. 게다가 매개변수로 레지스터 메모리를 사용하기라도 한다면 더더욱 이해하기 힘들어진다.
그래서 주석은 아무리 강조해도 지나침이 없다. 아까 설명했듯이 대표적인 주석은 세미콜론(;)인데, ;로 시작해서 그 줄의 끝까지가 주석이 된다. (이것을 가장 많이 쓰게 될 것이다.) 또다른 형태의 주석은, C에서 /* */와 같이 일종의 블럭안을 모두 주석으로 처리해 주는 것이다. 이는 다음과 같이 사용할 수 있다.
COMMENT !
This line is a comment.
Welcome to Internet.com
!
!대신에 &와 같이 사용자가 하고싶은 기호를 사용해도 된다. 이렇게 하면 COMMENT ! 와 !로 둘러싸인 부분이 모두 주석이 된다.
자료를 정의하는 방법을 배워보자. 쉽게 말해서 변수를 만드는 것이다. 그러기 위해서는 자료형을 알아야 한다. C에 int, long, float, double이 있는 것처럼, 어셈블리어에도 자료형이 있다. 다음의 표에 열거해 놓았으니 참고바란다.
|
Type |
Usage |
|
BYTE |
8비트 부호없는 정수 |
|
SBYTE |
8비트 부호있는 정수 |
|
WORD |
16비트 부호없는 정수 |
|
SWORD |
16비트 부호있는 정수 |
|
DWORD |
32비트 부호없는 정수 |
|
SDWORD |
32비트 부호있는 정수 |
|
FWORD |
48비트 정수 |
|
QWORD |
64비트 정수 |
|
TBYTE |
80비트 정수 |
|
REAL4 |
IEEE표준의 32비트 실수 |
|
REAL8 |
IEEE표준의 64비트 실수 |
|
REAL10 |
IEEE표준의 80비트 실수 |
C로 치면 변수 선언 방법이라고 할 수 있고, 다음과 같은 형식을 같는다.
이름 디렉티브 초기값, 초기값...이름은 생략될 수도 있다. 디렉티브는 표 2에 나온 것들을 말한다. 각각을 설명하자면, 먼저 맨 앞의 이름은 앞에서 이야기한 데이터 레이블이다. 레이블은 없을 수도 있다. 초기값이 여러개인 것이 궁금할 것이다. 초기값을 두 개 이상 쓰게 되면 그것은 메모리에 연속적으로 초기값의 개수만큼 공간이 할당되며 해당 초기값으로 초기화된다. 메모리에 연속적으로 위치하게 되므로, 메모리 주소 연산을 이용하여 일차원 배열처럼 사용할 수 있을 것이다. 이에 대한 예는 나중에 설명하도록 하겠다. 자료 정의에 대한 예는 다음과 같다.
value1 BYTE 'A' ; 문자 상수
value2 BYTE 0
value3 SBYTE ?디렉티브를 대문자로 쓴 것은 단지 보기 좋으라고 한 것이니까 신경쓰지말자. 대소문자는 구분하지 않는다고 했으니 소문자로 써도 상관없다. 값을 굳이 초기화하지 않아도 된다면 value3와 같이 초기값 자리에 ?를 사용할 수 있다.
C언어에서 배열에 문자열 넣을 때는 char string[25] = "abcdef"; 이런식의 사용이 허용된다는 것을 기억하는가? 어셈블리어도 문자열 정의에 있어서는 많은 배려를 해주고 있다. 다음을 보라.
greeting1 BYTE "Hi~>.<;",0 ; 1번위의 1번과 2번은 완전히 같은 것이다. 맨 뒤에 붙은 0은 무엇을 의미할까? 바로 문자열의 끝을 나타내는 것으로서 널문자라고 한다. 개행문자를 넣고 싶다면 해당 위치에 0Ah, 0Dh를 넣어야 한다. 도스에서는 캐리지리턴과 라인피드가 모여서 하나의 개행문자를 이루기 때문이다.
greeting2 BYTE 'H', 'i', '~','>', '.', '<', 0 ; 2번
연속된 여러 값들을 한꺼번에 초기화할 수 있게 해주는 연산자이다. 아까 한 데이터 레이블에 뒤이어 연속적으로 자료를 정의했던 것을 상기시켜보라. 만약 연속된 자료가 1000개 필요하다면 0을 1000개 써야 하므로 매우 귀찮을 것이다. 하지만 DUP연산자를 사용한다면 다음과같이 쓸 수 있다.
BYTE 1000 DUP(0) ; 20 bytes, 모두 다 0이다.
BYTE 4 DUP("ABC") ; 12 bytes: "ABCABCABCABC"
위의 용어는 메모리에 각 바이트가 저장되는 순서를 의미한다. 앞장에서 우리는 데이터를 비트를 쭉 늘어놓았을 때, 맨 왼쪽이 최상위비트, 맨 오른쪽이 최하위비트라고 배웠다. 마찬가지로 16비트, 즉 2바이트를 늘어놓았을 때에도 왼쪽에 있는 바이트는 상위 바이트, 오른쪽에 있는 바이트는 하위 바이트라고 할 수 있다.
리틀 엔디안 오더는 "하위 바이트가 하위 주소에 저장되는 방식"이다. 주소에 상위와 하위가 있다고? 상위라는 것은 단지 메모리 주소를 나타내는 숫자가 크다는 뜻이므로 헷갈리지 않기 바란다. 다음 그림을 참고하면 더욱 이해하기 쉬울 것이다.

왼쪽이 리틀 엔디안 오더이고, 오른쪽이 빅 엔디안 오더이다. 빅 엔디안 오더란, 리틀 엔디안 오더의 반대 개념으로서 "하위 바이트가 상위 주소에 저장되는 방식"이다. IA-32는 리틀 엔디안 오더를 사용하고 있다. 단, 레지스터 메모리에는 적용되지 않는 개념이니 주의하기 바란다.
C언어에서 #define을 쓰는 것과 같은 효과를 낸다. 다음을 보아라.
COUNT = 500
mov al, COUNT
TITLE Add and Subtract (AddSub.asm) |

위의 프로그램이 하는 일은 우선 eax에 10000h(16진수로 10000)을 넣고, eax에 들어있는 값에 40000h를 더한 후 20000h를 빼는 것이다. 그리고 나서 레지스터 메모리에 있는 내용을 화면에 출력시킨 후 프로그램을 종료한다. 한줄한줄 천천히 보자.
먼저, 맨 위에 TITLE부 터 설명하겠다. TITLE은 디렉티브이며, 큰 의미는 없고, 단지 이름이 타이틀이기 때문에 소스코드에는 아무런 영향을 안미치며, 해당 줄에 쓰는 것들(Add and Subtract....)은 모두 주석처리가 되는 것이다. 있어도 되고 없어도 되는 부분이지만 만약 없다면 프로그램을 읽기가 매우 힘들 것이다.
다음은 ;로 시작하는 부분인데 지난번에 주석이라고 배웠다.
INCLUDE Irvine32.inc은
C에 비유하자면 #include <irvine32.inc>와 같다. 필자가 참고도서로 언급한 책에서 제공되는
라이브러리를 사용하기 위해서는 이와같이 써야한다. 또한 링크 할 때도 irvine32.lib를 붙여주어야 한다. 혹시 필요한
독자가 있다면 deltakam@hanmail.net로 연락주기 바란다. 필요한 라이브러리와 어셈블러를 보내드리겠다.
.data라 는 부분이 나오는데, .data는 데이터 세그먼트의 시작 부분을 나타내는 디렉티브이다. 본 프로그램이 실행될 때 메모리의 데이터 영역에 올라가게 될 내용을 이곳에 적게 된다. 본 예제에서는 네가지 DWORD(더블워드)의 변수를 정의하여 놓았다.
.code라는 부분역시 디렉티브이고, 코드 세그먼트의 시작 부분을 나타낸다. 본 프로그램이 실행될 때 메모리의 코드 영역에 올라가게 될 내용을 이곳에 적으며, 실질적인 프로그램 제어 등이 이곳에서 이루어진다.
main PROC라는 것은 이름이 main인 프로시져의 정의가 이곳부터 작성될 것이라는 것을 알린다. C에서 함수의 헤더를 정의 앞에 적어주는 것에 비유해서 이해할 수 있다.
mov는 아까도 잠깐 설명했지만, 왼쪽에 있는 변수에 오른쪽에 있는 값을 저장하라는 인스트럭션이다. 코드의 첫 문장이 지났다면 이제 주석에서 보이는 대로 EAX에 10000h가 들어가게 될 것이다.
add는 왼쪽에 있는 변수의 값에 오른쪽에 있는 변수의 값을 더하라는 뜻이다. sub또한 마찬가지이다.
call DumpRegs는 irvine32라이브러리에 포함되어있는 프로시져 DumpRegs를 호출하는 것이다. 역할은 레지스터 메모리에 있는 내용을 화면에 출력시켜준다.
main ENDP는 이름이 main인 프로시져의 정의가 이곳까지라는 것을 나타낸다.
자세한 것은 나중에 다시 설명해 줄테니 일단은 이렇게 생긴 것이라고 이해를 해두기 바란다.
이번 회에서는 자세히 알지는 못하더라도, 개략적으로 어셈블리어가 어떻게 이루어져 있는지를 공부해 보았다. 디테일한 부분이 집착하지 않길 바라며, 혹시 레지스터 메모리가 헷갈린다 싶으면, 지난회를 다시 보기 바란다. 다음 회에서는 본격적으로 하나하나 인스트럭션과 유용한 디렉티브를 공부해 볼 것이다. 고급언어와의 연계를 생각하면서 강좌를 읽는다면 흥미를 유발할 수 있을 것이다. 그럼 다음 회에 건강한 모습으로 다시 뵐수 있길 빈다.
[출처] 어셈블리어 이해하기 < 강좌 소개 및 목차 >|작성자 멋쟁이
설정
트랙백
댓글
글
전광성의 어셈블리어 이해하기
* 이진수로 나타낸 부호있는 정수
컴퓨터는 음의 정수를 어떻게 표현하는가에 대해 알아보겠다. 컴퓨터는 -1을 만들기 위해 1에다가 2의 보수를 취한다. 2의 보수가 어떤 것인지는 다음 표를 보면 알 수 있다. 참고로 표에서 데이타의 크기는 1바이트이다. 또 비트반전은 1의 보수와 같은 말로서, 1은 0으로, 0은 1로 바꾸어주는 것을 의미한다.
| 1 |
0000 0001
|
|---|---|
| 비트반전(1의보수) |
1111 1110
|
| 더하기 1 |
1111 1111
|
| 결과 |
1111 1111
|
이번엔 거꾸로 해보겠다.
| -1 |
1111 1111
|
|---|---|
| 비트반전(1의보수) |
0000 0000
|
| 더하기1 |
0000 0001
|
| 결과 |
0000 0001
|
‘비트반전후 더하기 1‘하는 것을 ’2의 보수를 취한다‘ 라고 한다. 2의 보수를 취한 후 다시 2의 보수를 취하면 자기 자신이 된다는 것을 알 수 있다.
참고로, 최상위 비트가 1이면 음수고 0이면 양수가 된다. 즉 1111 1111은 음수고, 0111 1111은 양수이다. 2의 보수표현을 했을 때의 특징을 알아보자.
|
크다
|
-2
|
1111 1111
|
크다
|
|
|
-3
|
1111 1110
|
|
|
|
-4
|
1111 1101
|
|
|
|
-5
|
1111 1100
|
|
|
|
-6
|
1111 1011
|
|
|
|
-7
|
1111 1010
|
|
|
|
-8
|
1111 1001
|
|
|
|
-9
|
1111 1000
|
|
|
|
-10
|
1111 0111
|
|
|
작다
|
-11
|
1111 0110
|
작다
|
음수를 2의 보수표현으로 나타내면 숫자의 크기가 작아질수록, 실제 그 이진수의 크기는 작아짐을 알 수 있다. 따라서 이대로 가면 -128은 1000 0000이 될 것이라고 예측할 수 있다. 그것보다 한 숫자 작아지면 0111 1111이 되고, 이는 1바이트로 표현할 수 있는 최대값이 된다.
| 저장 종류(Type) | 사용하는 비트수 | 범위 |
|---|---|---|
| byte |
8
|
-(2의 7승) ~ 2의 7승 |
| word |
16
|
-(2의 15승) ~ 2의 15승 |
| doubleword |
32
|
-(2의 31승) ~ 2의 31승 - 1 |
| quadword |
64
|
-(2의 63승) ~ 2의 63승 - 1 |
상식적으로, 최상위비트로는 부호부분을 나타내고 나머지 비트들로 숫자부분을 나타내는 것이 편하다고 생각할 수도 있다. 하지만, 위의 표를 보라. 2의 보수표현을 하면 음수에서 대소관계가 그대로 지켜진다. 2의 보수표현이 좋은 이유가 한 가지 더 있는데 이는 다음에서 알아본다.
컴퓨터는 ‘뺄셈’은 할 줄 모른다. 그럼 뺄셈을 어떻게 할까? 바로 앞에서 배운 2의 보수를 취하는 방법을 이용한다. 컴퓨터가 A-B를 계산해야 한다고 하자. 그러면 컴퓨터는 A + (-B)를 한다. 여기서 B에 -부호를 붙인다는 것은 2의 보수를 취한다는 것이다. 2의 보수표현방법의 강력한 장점중의 하나는 이 뺄셈에서 드러난다. A + (-B)로 함으로써 빼기 연산을 따로 만들 필요 없이, 음수표현 방법을 그대로 이용하여 계산할 수 있다는 것이다. 예를 들어보겠다.
a. 4 0000 0100 b. 1 0000 0001 c. -1 1111 1111 a+c 3 0000 0011
보다시피 a - b는 a + c와 같다. 마지막 단계에서 8비트를 넘어선 비트8(왼쪽에서부터 9번째 비트)에 넘어간 숫자는 어디갔을까? 컴퓨터는 지금 8비트(1바이트)형의 데이터에 대해 연산을 하고 있으므로, 이 범위를 벗어난 것은 그냥 버린다.
컴퓨터는 0과 1밖에 모른다. 그런데 어떻게 문자를 표현할까? 문자를 표현하기 위해 아스키(ASCII)코드라는 것이 정의 되어있다. 128가지를 표현할 수 있으며, 각 코드는 숫자와 문자를 일대일 대응 시켜놓았다. 따라서 48에 대응되는 문자를 출력하라고 하면 미리 대응시켜놓았던 그 문자가 표시되도록 하는 방식으로 문자를 처리한다.
표현 방법이 어떻든 간에 컴퓨터는 숫자로 이루어져 있다는 사실을 명심하라. 우리 눈에 보이는 a는 눈에만 문자로 보이지 사실은 65라는 숫자값이다. 다음은 자주쓰는 문자에 대한 아스키 코드값이다.
| 문자 | 아스키코드값 |
|---|---|
|
0
|
48
|
|
9
|
57
|
|
A
|
65
|
|
Z
|
90
|
|
a
|
97
|
|
z
|
122
|
0~9, A~Z, a~z은 각각 오름차순으로 아스키코드에 들어가 있다. 따라서 문자의 대소를 비교할 때(예를 들면, 오름차순 정렬) 이에 대응하는 아스키 코드 값으로 대소를 비교할 수 있다.
컴퓨터를 아무리 깊이 모른다고 해도 이진 연산 쯤은 알고 있을 것이다. 수학에서도 가장 기초적인 개념으로 나오니 말이다. 이진수에 대한 AND, OR, NOT연산에 대해서는 간단히 표를 보여주고 넘어가겠다. 여기서 F는 false(거짓, 0)을 의미하고 T는 true(참, 1)을 의미한다. X, Y는 이진 변수로서 1 또는 0의 값을 가질 수 있다.
| X | Y | X AND Y | X OR Y | NOT X | NOT Y |
|---|---|---|---|---|---|
|
T
|
T
|
T
|
T
|
F
|
F
|
|
T
|
F
|
F
|
T
|
F
|
T
|
|
F
|
T
|
F
|
T
|
T
|
F
|
|
F
|
F
|
F
|
F
|
T
|
T
|
이번 회에서는 어셈블리어를 배우는데 있어 필수적인 기본 컴퓨터 '상식'들에 대해 공부해 보았다. 상식이라고 해서 크게 부담 가질 것 없다. 모를때 자꾸자꾸 다시 보다 보면 어느새 내 것이 되어있을테니까. 다음시간에는 CPU와 관련된 내용을 알아볼 것이다. 어셈블리어가 어떻게 CPU에 직접 접근하는지, 다음 강좌를 통해 알아보도록 하자!!
[출처] 어셈블리어 이해하기 < 강좌 소개 및 목차 >|작성자 멋쟁이
설정
트랙백
댓글
글
자, 이제 이진수를 이용하여 자료를 표현해 보자. 우선은 제일 쉽고 간단하면서도 흔한 부호없는 정수에 대해 생각해보자. 부호없다는 것은 ‘음이 아닌 정수’라는 뜻이다. 그럼 음수는?... 다음 단락에서 다룰 것이니 걱정마라.
우선은 2진수를 어떻게 10진수로 변환하는지 알아보자. ㅁㅁㅁㅁ ㅁㅁㅁㅁ 이렇게 8비트의 이진수가 있다고 하자. 아까 비트에 번호붙였던 것이 기억나는가? 8비트니까 맨 왼쪽이 비트7, 맨 오른쪽이 비트 0이다. 10진수로 변환하려면
비트7 * (2의7승) + 비트6 * (2의 6승) + 비트5 * (2의 5승) + 비트6 * (2의 6승) + ... + 비트1 * (2의 1승) + 비트0 * (2의 0승)
이렇게 하면 된다. 그런데 가만보자... 비트0이든 비트1이든 한 비트는 0 아니면 1이다. 그럼 조금 바꿔서 생각하면... 비트가 1인 자리수만 더해주면 된다. 0은 뭘 곱해도 0이 될테니까 덧셈에 아무런 도움을 주지 않을 것이다. 그렇다면 아예 (2의 □승)에 대한 표를 만들고 그것을 보고 변환하는 게 편할 것이다. 하지만 굳이 표를 그리진 않겠다. 왜냐하면 별 쓸모가 없기 때문이다.
2진수는 너무 공간을 많이 차지해서 대부분 16진수로 변환해서 사용한다. 16진수는 또 무엇일까? 후에 설명하도록 하겠다. 일단은 진법을 변환하는 개념에 대해서만 알면 된다.
이번엔 역으로 10진수를 2진수로 변환하는 방법을 알아보겠다. 방법을 직접 설명하기엔 너무 비효율적이므로 하나의 예를 들겠다. 37을 2진수로 표현해 보자.
| 나눗셈 | 몫 | 나머지 |
|---|---|---|
| 37 / 2 | 18 | 1 |
| 18 / 2 | 9 | 0 |
| 9 / 2 | 4 | 1 |
| 4 / 2 | 2 | 0 |
| 2 / 2 | 1 | 0 |
| 1 / 2 | 0 | 1 |
위에서부터 한줄씩 내려가며 계산한 것이다. 한번 계산했을 때의 몫이 다음 계산에서 이용된다. 몫이 0이 될때까지 반복한 후, 나머지를 맨 아랫줄에서부터 맨 위로 읽으면 된다. 따라서 100101(2) 가 된다. (뒤에 (2)는 이진수라는 뜻이다.)
다음은 저장 크기다. 저장크기라고? 몇 자리, 즉 몇 비트로 숫자를 표현하느냐에 따라 얼마나 큰 숫자를 저장할 수 있는지가 달라질 것이다. 당연히 많은 자릿수, 즉 많은 비트로 숫자를 표현하면 더 큰 숫자를 표현할 수 있다. 인텔 CPU에서 사용할 수 있는 부호없는 정수의 저장 크기는 다음 그림과 표에 정리해 놓았다.

<그림 1 : 데이터형과 그 크기>
| 저장 종류(Type) | 사용하는 비트수 | 범위 |
|---|---|---|
| Unsigned byte |
8
|
0~(2의8승 - 1) |
| Unsigned word |
16
|
0~(2의 16승 - 1) |
| Unsigned doubleword |
32
|
0~(2의 32승 - 1) |
| Unsigned quadword |
64
|
0~(2의 64승 - 1) |
조금 센스있는 분이라면, [2의 (사용하는 비트수)승] - 1은 해당 범위의 최대값이라는 것을 발견할 수 있을 것이다. 뒤에 왜 1을 빼는지는 범위가 0부터 시작한다는 데서 찾을 수 있을 것이다. 또 8비트가 1바이트라고 표에 나와 있으므로, 2바이트는 워드, 4바이트는 더블워드, 8바이트는 쿼드워드라는 것을 눈치채야한다.
아까 알려주기로 했던 16진수에 대해 알아보자. 16진수는 0~9와 A~F까지의 16가지 문자를 이용하여 숫자를 표현하는 것이다. 각각 A는 10을, B는 11을, C는 12를, D는 13을, E는 14를, F는 15를 의미한다.
| 10진수 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
16진수
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
A
|
B
|
C
|
D
|
E
|
F
|
16진수를 왜 쓰는지 생각해 보자. 대답은 간단하다. 16진수는 2진수보다 더 짧은 길이로 큰 수를 표현할 수 있기 때문이다. 그럼 왜 10진수도 11진수도 12진수도 아닌 딱 16진수일까? 그것은 바로 2의 4승이 16이기 때문이다. 이해가 가지 않는가? 그럼 다음 예를 보아라.
A6(16진수) = 1010 0110 (2진수)
2진수에서 가운데 공백을 넣은 것은 네글자씩 끊어서 보기 편하게 하려고 한 것이다. A는 10을 나타낸다고 아까 말했다. 2진수에서 상위 네 비트를 10진수로 바꿔보자. 10이 된다. 아까 A가 1010과 같다는 뜻이 된다.
뭔가 눈치를 챘을 것이다. 2진수에서 네 비트는 16진수 한 자리와 대응 된다. 마찬가지로 6은 0110과 같다. 그러면 이제 16진수를 왜 쓰는지 알 수 있을 것이다. 2진수와의 변환이 간편하다는 점이다. 그냥 네 비트씩 끊어서 16진수로 바꾸면 된다. 왜 그런지는 각자 생각해 보기 바란다.
여기서 간단한 팁 한가지를 알려 주겠다. 8421코드라는 변환 방법인데, 알고 있으면 정말 편하다. 즉 이진수 네 비트가 있다고 할 때 상위 비트부터 하위 비트까지 8421이 하나씩 대응되는 것이다. 이진수 1111은 8 + 4 + 2 + 1이다. 1001은 8 + 1이다. 8421을 언제나 머릿속에 넣어두어라. 이진수를 보고 16진수로 바꿀 때, 8421코드를 이용하여 각각의 네 비트를 10진수로 만든 후 16진수로 바꿔라. 이진수에서 16진수로 바꾸기가 편해질 것이다.
[출처] 어셈블리어 이해하기 < 강좌 소개 및 목차 >|작성자 멋쟁이
설정
트랙백
댓글
글
어셈블리어는 저급언어다. 원론적으로 이야기 하자면, 사람보다는 기계에 더 친한 언어이다. 이 언어는 대부분 하드웨어에 직접 명령을 내리는 형식을 갖추고 있고, 고급언어에서 신경 쓰지 않아도 되었던 것들에 대해서 일일이 신경 써 주어야 한다. 그렇기 때문에 기본 개념이 필요하다.
중학생 시절, 내가 C언어 책을 사서 공부하는 것을 보고 나의 친형이 경쟁심에 더 어려운 것을 해보겠다며 어셈블리어 책을 샀던 것이 기억난다. 형은 앞에만 조금 읽다가 재미없다고 책을 덮어버린 적이 있었다. 어셈블리어를 제대로 배워보겠다는 생각은 가져보았으나, 재미가 없어서 포기하는 경우가 많다.
어셈블리어를 배우다가 가장 장애가 되는 것은 ‘이런 것을 내가 왜 배울까?’ 하는 생각일 것이다. 어셈블리어를 배운다는 것은 단지 언어를 배울 뿐만 아니라, 기초적인 컴퓨터 구조의 원리를 익히는 과정이다. 정 지루하다면, 다른 프로그래밍 언어를 어셈블리어로 구현할 때 어떻게 해야 할지 상상해 가며 강좌를 읽어주기 바란다. 물론 하드웨어를 하는 분이시라면 굳이 그런 의문이 없을 테지만.
본 회에서는 매우 기본적인 개념을 다룬다. 컴퓨터관련 자격증 필기시험을 한번이라도 보았다면, 쉽게쉽게 이해할 수 있을 것이다. 그렇지 않더라도, 상식선에서 해결될 내용이니 걱정할 필요 없다. 부담없이 강좌를 봐주길 바란다.
어셈블리어란 기계어를 영문자로 치환시킨 언어이다. 예를 들어 45라는 명령이 있는데 이 명령이 숫자의 대소를 비교한다고 치자. 그렇다면 45라는 명령을 cmp와 같이 comparison의 약자로 대신 사용하는 것이다. 기본적으로 기계어는 모두 숫자이기 때문에 코드를 볼 때 이해하기도 힘들 뿐더러, 숫자로 된 그 많은 기계어들을 일일이 매뉴얼을 참고해 가며 프로그램 작성하기도 힘이 든다. 이런 불편함을 해소하고자 어셈블리어가 탄생하게 되었다.
어셈블리어와 고급언어의 구체적인 차이는 <표1>에 설명해 놓았다.
| 프로그램 | 고급언어 | 어셈블리어 |
|---|---|---|
|
한 플랫폼에서만 돌아가는 대규모의 응용프로그램
|
규모가 큰 코드를 유지 및 보수하기 좋은 구조를 갖고있다.
|
코드의 유지보수가 어려운 구조를 갖고 있으며, 개발에 많은 경험을 필요로 한다.
|
|
하드웨어 장치 드라이버
|
직접적인 하드웨어 접근이 힘들다.
|
하드웨어로의 접근이 직접적이고 간단하므로, 유지보수가 편하다.
|
|
여러 플랫폼에서 작동가능한 응용프로그램
|
보통 호환성이 뛰어나서, 약간의 코드 수정만으로 다른 플랫폼에 이식 가능하다.
|
각각의 플랫폼마다 다른 어셈블러로, 다른 문법으로 작성해야한다.
|
|
직접적인 하드웨어 접근이 필요한 임베디드시스템과 컴퓨터게임
|
하드웨어로의 접근이 매우 느려 수행속도에 문제가 있다.
|
하드웨어에 직접적인 접근을 하기 때문에 수행속도가 빠르다.
|
위의 내용이 이해가 가지 않더라도 겁먹을 필요 없다. 필자가 C언어를 배울 때 포인터에서 막혀 책을 덮은 것이 한두번이 아니었다. 나는 포인터를 왜 쓰는지 너무나 궁금해서 게시판 여기저기를 돌아다니며 질문을 해보고 당시 나우누리에서 강좌를 쓰시던 분에게도 메일을 보내 봤지만 통쾌한 대답을 얻을 수 없었다. 그러다가 포기하는 심정으로 포인터 뒷부분으로 계속 진도를 나가다 보니 왜 쓰는지는 물론 어떻게 활용해야 할지도 알 수 있었다.
공부를 하다가 중간에 모르는 것이 생기면 일단은 그곳에 물음표를 달아놓고 지나가면 된다. 더 진도를 나간 후 다시 보면 이해할 수 있는 경우가 대부분이기 때문이다.
컴퓨터는 자료를 어떻게 표현할까? 우선 자료가 무엇인지 생각해 보자. 자료는 컴퓨터로 우리가 정보를 활용하기 위한 값이다. 이것은 어떤 수치값이 될 수도 있고, 숫자가 될 수도 있다. 이러한 자료중 연관된 것을 일정 형식으로 잘 모아서 놓는다면 그림에 대한 정보를 가질 수 있고, 한 학생에 대한 정보를 가질 수도 있다. 또, 어떤 3D객체를 나타내기위해 필요한 정보를 가질 수도 있을 것이다. 정보이기 이전에 자료가 있다. 이제 이 자료를 컴퓨터에서 어떻게 표현하는지 알아보자.
컴퓨터가 자료를 어떻게 표현하는지를 알려면 우선 이진수를 빼놓을 수가 없다. ‘컴퓨터는 0과 1밖에 모른다’라는 말은 한번 쯤 들어 보았을 것이다. 그렇다. 정말로 컴퓨터는 0과 1밖에 모른다. 우리가 고급언어로 프로그래밍 할 때는 컴퓨터가 0과 1밖에 모른다는 것이 그다지 와 닿지 않을 수도 있다. 대부분의 고급 언어는 이진 연산은 제공해도, 이진수를 직접 상수로 사용할 수 없다.
하지만 어셈블리어는 이진수를 직접적으로 제어할 수 있고, 이진수를 직접 상수로 사용할 수 있다. 그만큼 다른 언어보다 이진수를 가까이 하고, 이진수 차원의 제어를 필요로 하는 언어가 어셈블리어이다.
10진수는 0~9까지의 열 가지 숫자를 이용하여 숫자를 표현한다. 반면 이진수는 0~1까지의 두 가지 숫자만을 이용하여 숫자를 표현하는 것이다. 이진수의 한 예를 보여주겠다.
(15) (0) 1011001010011100
위에 괄호로 쓴 숫자는 무엇일까? 각각의 숫자에 번호를 매긴 것이다. 그 각각의 숫자 하나를 ‘비트(bit)'라고 한다. 위에 있는 이진수는 몇자리 숫자일까? 그렇다. 16자리 숫자이다. 그렇기 때문에 위의 이진수를 컴퓨터로 표현할 때는 16bit라고 한다. 16자리니까 16비트인 것이다.
비트에 숫자를 매긴 것을 다시 보자. 15는 맨 왼쪽, 그러니까 제일 높은 자리수를 나타내고 ’비트15‘라고 부른다. 또 이 숫자에서 제일 높은 자리 숫자이기 때문에 '최상위 비트' (MSB: Most Significant Bit)라고 한다. 한글로 하면 ’최상위 비트‘이다. 0은 맨 오른쪽의, 그러니까 제일 낮은 자리수를 나타내고 ’비트0‘이라고 부른다. 또 이 숫자에서 제일 낮은 자리 숫자이기 때문에 '최하위 비트' (LSB: Least Significant Bit)라고 한다. 한글로 하면 ’최하위 비트‘이다.
갑자기 많은 개념이 들어가서 헷갈리는가? 걱정말기 바란다. 나중에 나오면 다시 설명해 줄 것이다.
[출처] 어셈블리어 이해하기 < 강좌 소개 및 목차 >|작성자 멋쟁이
설정
트랙백
댓글
글
1. 강좌 소개
본 강좌에서는 어셈블리어(Intel-based Assembly Language)를 배울 것이다. 고급언어 중에서도 특히 객체지향언어를 활용하는 지금, 굳이 어셈블리어를 배워보려는 이유는 무엇일까?
첫
번째 이유는 어셈블리어가 여전히 하드웨어 컨트롤과 커널 개발 등에 쓰인다는 것이고, 두번째 이유는 이것을 배움으로써 CPU가
어떤 일을 하는지, 컴퓨터가 어떻게 프로그램을 수행하는지 알 수 있다는 것이다. 프로그래밍 언어를 한번이라도 접해본 사람이라면
쉽게 이해할 수 있도록 설명할 예정이다.
어셈블러로는 매크로어셈블러(masm)6.15을 사용할 것이며, 아래 참고자료에 있는 라이브러리를 이용하여 예제를 보여줄 것이다. C에서 처음에 printf()함수를 이용해서 기초를 쌓듯, 우린 이 라이브러리를 이용해서 차근차근 배워갈 것이다.
* ASSEMBLY LANGUAGE FOR INTER-BASED COMPUTERS
written by KIP R. IRVINE, Prentice Hall
2. 강좌 목차
1회 : 어셈블리어를 배우기 위한 기본 개념
어셈블리어가 대체 무엇을 하는 놈인지 알아본다. 또 기본적인 컴퓨터의 자료 표현방법과 불린 연산에 대해 쉽게 알려준다.
2회 : IA-32 프로세서 아키텍쳐(Processor Architecture)란?
과연 저 복잡한 단어는 무엇을 의미할까? 그 해답을 얻기 위해서는 우선 CPU에 대한 지식이 필요할 것이다. 또, 앞으로 눈에 박히도록 나올 레지스터 메모리에 대해 자세한 설명을 덧붙인다.
3회 : 어셈블리 언어 기초
어셈블리어를 이용해 뭔가 결과물을 보여줌으로써 시작한다. 기초적인 어셈블리 문법을 배우기 시작할 텐데, 어셈블리의 자료형에 대한 언급도 빠질 수 없을 것이다.
4회 : 기본 명령어
이제부터는 앞의 내용을 모르면 보기 힘들다. 덧셈과 뺄셈, 배열과 문자열의 간단한 사용에 대해 알아본다. 또 프로그래밍 언어에서 빠질 수 없는 루프에 대해 살펴본다.
5회 : 프로시져(Procedure)
이제 프로그램을 구조적으로 짤 수 있게 해주는 프로시져를 배운다. 프로시져가 성립되기 위해서는 런타임 스택이라는 것에 대한 언급이 필요하다.
6회 : 조건 처리
CPU가 숫자를 비교하는 방법에 대해 살펴본다. 이를 토대로 조건에 따라 점프하기, 조건에 따라 루프돌기 등의 명령어를 알아본다.
7회 : 정수 산술연산(이진연산)
쉬프트 연산에 대해 살펴볼 것이다. 또 덧셈보다 복잡한 곱하기, 나누기에 대해 알아본다.
8회 : 고급 프로시져
프로시져를 좀더 멋있게 호출하기 위해 지역변수개념과 스택 파라미터등에 대해 파헤쳐 본다. 또 그 유명한 재귀호출도 설명한다.
9회 : 스트링과 배열
스트링을 정밀하게 다룰 때 쓰이는 명령들에 대해 공부한다. 또 이차원 배열과 문자열 소팅에 대해서 살펴본다.
10회 : 구조체와 매크로.
어셈블리어에서 구조체를 어떻게 구현할지에 대해 고민해보자. 또 어셈블리어를 좀더 멋지게 꾸밀 수 있는 매크로와 조건-어셈블리 지시자들에 대해서도 공부해본다.
11회 : 32비트 윈도우즈 프로그래밍
윈도우에서의 콘솔프로그래밍에 대해 공부한다. 그 다음, 그래피컬 윈도우 어플리케이션을 어떻게 하는지, 메모리 매니지먼트는 어떻게 되는지 자세히 살펴본다.
12회 : 고급언어 인터페이스
고급언어와의 연계를 목표로 한다. 다른 언어에서 사용할 수 있는 inline-assembly코드에 대한 공부를 한다. 특히, C++과의 연계에 대해 살펴본다.
[출처] 어셈블리어 이해하기 < 강좌 소개 및 목차 >|작성자 멋쟁이
설정
트랙백
댓글
글
| log 0^0 = 0 * log 0 인데요 여기서 log0은 정의가 없습니다. 따라서 0+h, limh->0 log(0+h) =0×(-∞) 이렇게 정의를 내려야 하는데요. 0 * (-∞) 의 값은? 알수없다입니다. 따라서 0^0도 존재하지 않습니다. 간단한 이유를 들면요. x^0은 x를 아직 한번도 안곱한것이죠 x를 곱하기 전의 상태를 말하기 때문에 x의 0승은 곱셈에대한 항등원인 1을 말합니다.. 하지만 0은 곱셈에 대한 항등원이 모든수이기 때문에 그 값을 정할수 없습니다 |
결국 0의 0제곱은 부정이 됩니다.
설정
트랙백
댓글
글
0!=1인 세가지 이유...
|


RECENT COMMENT